GSoC [02]: Basic needs fulfilled!
· 6 min read
![GSoC [02]: Basic needs fulfilled!](/assets/images/journey.jpg)
The first of the three phases of coding is about to end. And the evaluations for this phase start from 24th June. This post contains the synopsis of my work during the first four weeks.
Where do we want to be? 🌘
A question we need an answer to, before starting anything.
Let’s start with that. It won’t be fair if I talk a blue streak
about what I have done without discussing what I want to do.
The project co-oCCur aims to address the
issue: “misalignment of subtitles with the base audiovisual
content”. There are two use cases that the project currently
aims to tackle leveraging two different approaches using
two tools, namely Tool A and Tool B.
My
proposal
elucidates the approach of tackling both the cases and the
architecture of both the tools in depth. In a nutshell,
Tool A will use
audio-fingerprint
annotations while Tool B will create two strings
(an audio string and a subtitle string), to detect a
constant temporal offset responsible for the misalignment.
Adjustment of the subtitles will be achieved by propagating
a time delay in each of the caption entries in the subtitle
document. The resulting subtitle document will have a
different presentation time for each caption entry so that the
audio and the subtitles co-oCCur.
Tool A
Use case: Synchronization of subtitles between two versions
(for example, with and without commercials)
of the same audiovisual content. It will take as input the
original audiovisual content, the edited audiovisual content
and the subtitles document of the original audiovisual content.
Tool B
Use case: Synchronization of subtitles between two versions
of the same audiovisual content in the absence of the
original content. It will take as input the modified audiovisual
content and the subtitle document for the original
audiovisual content.
The whole project has been divided into modules and sub-modules. The function of each of which I have described in my proposal in great detail. During the first coding phase, I had decided to work on all the basic utility modules.
How's the Subtitle Synchronization coming along? ️️⏳
 These were the proposed deliverables for the first evaluations.
I have also created a Trello board to make it easier for my mentor and myself, to keep a track of my progress.
These were the proposed deliverables for the first evaluations.
I have also created a Trello board to make it easier for my mentor and myself, to keep a track of my progress.
Project link:
github.com/sypai/co-oCCur
Trello:
trello.com/co-occursubtitlesynchronization
As I had mentioned in the last post, my final examinations started from the very same day the coding period began, which made everything a bit cluttery in the first two weeks. I could not devote the time I planned and needed to meet the deadlines. As a result, tasks were getting postponed. But somehow after a few sleepless nights, lots of coffee and an endless loop of good music later, things have got on track, at least I feel so.
Here are the tasks I checked off during the first coding phase:
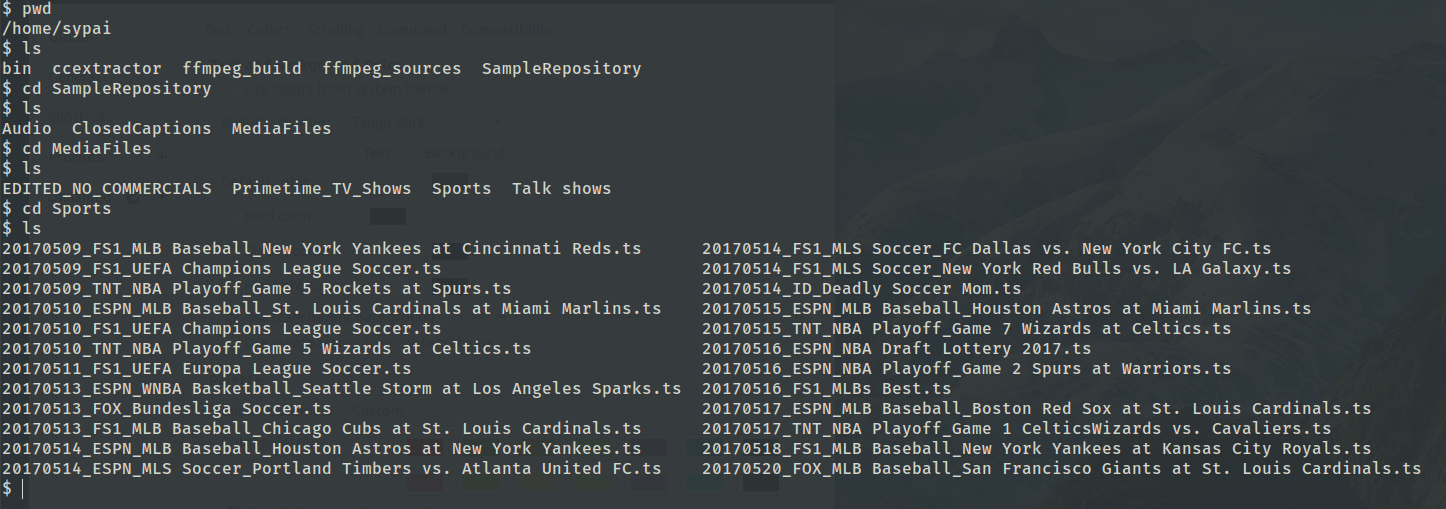
Sample Repository ✔️
The first task in hand was to collect samples, a lot of samples.
I had mentioned this as a requirement in my proposal.
I informed my mentor @cfsmp3
and he gave me access to
a high-speed development server (gsocdev3) which has a
huge sample collection. FFmpeg and CCExtractor are the
tools I used to extract audio and subtitles & collected them
in a SampleRepository. For our project, the audio needs to
have certain specifications. It needs to be uncompressed,
raw PCM (16 bit-signed int), mono sampled at 16000 Hertz.
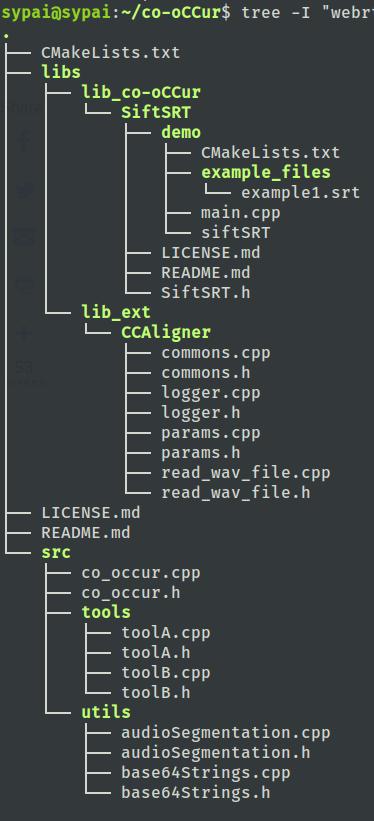
Basic Architecture ✔️
This is how the co-oCCur repo currently look like:
Base64 encrypt and decrypt ✔️
[Tool A] The fingerprints extracted from the audio will be 32-bit integer
vectors and this is the form we will use while comparing them later.
But in the subtitle document they will be stored as base64 strings.
Task of converting these integer vectors to base64 strings and vice versa
has been completed.

SiftSRT ✔️
SiftSRT: A complete subtitle parser and editor
(Check it out!).
Whatever our Tool A and Tool B require, related to subtitle files,
SiftSRT has got it covered!.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
SubtitleParserFactory *spf;
spf = new SubtitleParserFactory("inputSubtitle.srt");
SubtitleParser *parser;
parser = spf->getParser();
std::vector<SubtitleItem *> sub;
sub = parser->getSubtitles();
co_oCCurEditor *edit;
edit = new co_oCCurEditor(sub);
co_oCCurParser *parse;
parse = new co_oCCurParser(sub);
- AFInserter
[Tool A] Our audio fingerprinting library Dactylogram (Phase 2) will extract audio fingerprints annotations from the original audio and then they will be inserted into the original subtitle document as fingerprint anchors and create an enriched subtitle document.
1
edit->EnrichSRT("temp.srt", fingerprints, timestamps);
- AFSeeker
[Tool A] For comparing our fingerprints extracted from modified audio with the fingerprint anchors we will need the anchors. Our Subtitle parser will give that.
1
2
auto FPs = parse->getFingerprints();
auto FPTime = parse->getFPTimestamps;
- Subtitle Segmentation
[Tool B] As mentioned we need a subtitleString containing information about subtitles1 = Subtitle present in the window0 = No subtitle in the window
1
2
int timeWindow = 10;
auto substring = parse->SpeechActivityDetection(timeWindow);
- Subtitle Adjustment
[Tool A][Tool B] The last step in both tools is adjusting the subtitle file using the constant temporal offset detected by respective algorithm. As we get thedelaywe propagate it to each caption entry.
1
edit->AdjustSRT("example.srt", delay, true);
VAD Implementation ✔️
[Tool B] Out of the required two strings for alignment audioString contains information
of voice activity in a time window for the modified audio.
This requires Voice Activity Detection. Google’s open-source
WebRTC has a VAD
module which uses Gaussian Mixture Model (GMM). I have used that for creating our
audioString.
1 = Subtitle present in the window
0 = No subtitle in the window
1
2
std::vector<int16_t> samples = file->getSamples();
implementVAD(samples);
How does everything fall into place? 🧩
All the basic needs of the project have been fulfilled.
The figures below describe the workflow of the Tools.
✔️ represents which parts of the workflow have been completed.
Tool A
.png)
Tool B
.png)
Road ahead 🛣
Now I will begin working on Dactylogram, the most interesting, challenging and
presumably time-taking part of the whole project. The goal is to develop
an audio fingerprinting library required for Tool A. In the workflow above, the
blocks named AFExtractor & Seeking would be the TO-DO for the
second phase.
All the best to all the participants for the first evaluations.
I hope all of us pass with flying colors. 🤞 👍
See you on the other side!