GSoC : Final Work Submission!
· 5 min read

Surreal! My first Google Summer of Code has now come to an end. After almost 5 months (including the research pre-GSoC) it’s time to pack up. This has been a journey full of learning. This post is to serve the purpose of the final report for the work I have done during the summer.
Important links ⛓
-
Project repository
Subtitle-Resync @ Github -
Milestone & deliverable Board
Subtitle-Resync @ Trello -
Project proposal
co_oCCur/gsoc_19_ccx_proposal -
Organization
CCExtractor Development
Subtitle-Resync: High-speed subtitle synchronization
For an ideal subtitle file, the subtitles are perfectly aligned with the base audiovisual content. In other words, the audio and the corresponding subtitles co-oCCur. The misalignment of the subtitle files is the underlying problem that this project aims to solve so that the viewer does not have any burden before the fun starts (this is what matters).
Use case
Synchronization of subtitles between two versions
(with and without commercials) of the same
audiovisual content. It takes as input the original audiovisual
content, the edited audiovisual content and the subtitles
document of the original audiovisual content.
What has been done?
The whole project had been divided into modules and sub-modules. Can be seen in the Trello board, the function of each of which I have described in my proposal in great detail.
SiftSRT ✔️
SiftSRT: A complete subtitle parser and editor
(Check it out!).
Whatever our Tool A and Tool B require, related to subtitle files,
SiftSRT has got it covered!.
Dactylogram ✔️
The complete
audio-fingerprinting
solution for Tool A, using
chromaprint
.
Audio Segmentation ✔️
Determination of presence of speech in an audio using
webrtc
for Tool B.
Alignment Algorithm ️
-
Behind the scenes! ✔
There is a lot going on under the hood. Everything about the working and more can be found in this post. Internally, the audio fingerprints that dactylogram generates are array of 32-bit integer. We don’t really work with them in this form, but the hashes look something like this:1 2 3 4
array([3594440902, 3594416326, 3598545270, 3598528806, 3615303462, 3615435574, 3589233430, 3589233495, 3622787783, 3622794949, 3623867085, 3623862925, 3623867357, 3590189549, 3573346669, 2499605615, 2498559022, 2490230894, 2490230910, 2490362974])
These fingerprints are treated usually on bit level. So it’s more useful to think of the fingerprint as a 2D black-and-white image where each white represents a 1 bit and each black pixel is a 0 bit:

We use a small subset of bits from the hashes and cross-match the two fingerprints. For each hash that appears in both fingerprints, we will calculate the difference of offsets at which they appear in the fingerprints. We will build a histogram of these offset differences, do some filtering (effectively estimating a density function using gaussian kernels) and find peaks in it. The peaks will tell us how do we need to align the two fingerprints to find matching segments in them.
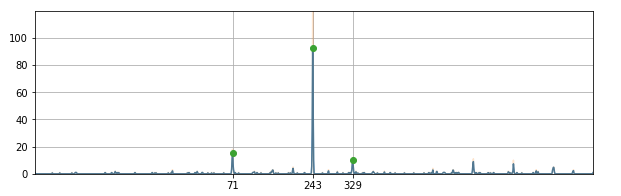
Using the alignment algorithm our tool detects the multiple segments in the original file, separating the actual audiovisual content and the commercials. Once the segments are identified we use SiftSRT to edit the subtitle document and create a perfectly aligned subtitle file.
Where do we stand?
At this point, we have a perfectly working tool, capable of doing
exactly what it is supposed to do.
Installation
- Clone the repository from
Subtitle-Resync @ Github
1
git clone https://github.com/CCExtractor/Subtitle-Resync.git
- Navigate to
installdirectory and runbuild.sh:
1 2
cd install ./build.sh
The tool is now ready to use!
Usage
For a complete list of options and parameters, please
go through the project’s
README
.
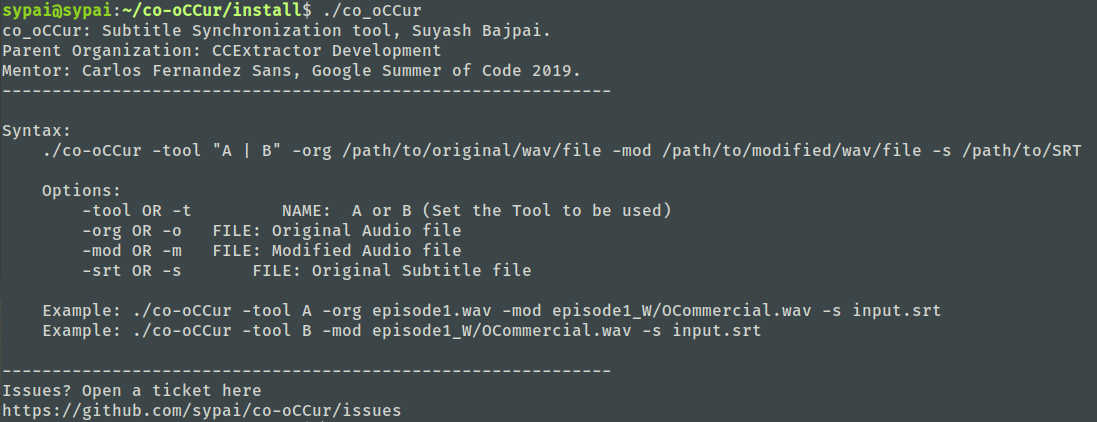
- Running Subtitle-Resync without any instruments lists all the parameters that are to be passed.
1
./resync -o /path/to/original/audio.wav -m /path/to/modified/audio.wav -s /path/to/original/subtitle.srt
- Sync!
1
./resync -o /path/to/original/audio.wav -m /path/to/modified/audio.wav -s /path/to/original/subtitle.srt
What will this trigger?
- Read the original audio and modified audio.
- Extract audio fingerprints from the audio files.
- Compare the fingerprints and detect the different segments in the original content.
- Adjust the subtitle file and generate an in-sync subtitle file.
See it in action:
What else can been done?
The project is in it’s early stage and will keep evolving. The available functions, usage instructions et cetera are expected to refactor over time. There are several ideas and features that can be added to this project.
- Currently only SRT is the subtitle format that this project supports. Support for other formats can be added.
- The misalignment of subtitles because of different encoding settings in videos causes a varying temporal offset. This is
also a great feature to add in to our project.
Also, contribution of any kind is more than welcome. Feel free to raise an issue tracker here: here .
GSoC: Endgame
Before the final goodbyes, I would like to thank my mentor,
Carlos Fernandez Sanz
for accepting my proposal,
providing guidance whenever I asked, and believing in me when things didn’t go as intended. I am grateful.
Shout out to the CCExtractor community for being so welcoming and supportive.
I am fortunate to be a part of the
CCExtractor Development
End? No, the journey doesn’t end here, it begins.. I’m sure I will stick around as a regular contributor.
"I pledge my life and honor to the Night's Watch, for this night and all the nights to come."