Subtitle Resync: Using Audio fingerprinting to synchronize subtitles
· 7 min read
Closed Captions (CC) and subtitles enhance an audiovisual content by providing speech information and description of representative events in a textual format.
Captioning is especially used as an aid for people with hearing loss or deafness, but it’s use
is definitely not limited to that domain. For instance, it is frequently the case that captions are necessary
to watch a TV show in a noisy surrounding or when one is not familiar with the language or accent
available in the audio streams.
For an ideal subtitle file, the subtitles are perfectly aligned with the base audiovisual content.
For subtitles to align their timing must align with the corresponding sequence in the audiovisual content.
There is a very common case in which we have an audiovisual content with some parts of the previous
episode, a lot of commercials throughout and some seconds of the next episode. More commonly a .ts, a transport
stream file involves such use case. The subtitles extracted from it will contain the subtitle for all the parts including the commercials.
Now we don’t ever use such videos instead we prefer clean recordings devoid of any commercials or breaks in it.
Now using the original subtitles will result in a horrible experience causing a sustained exasperation
to the user.
The tool Subtitle Resync takes in the two versions of the same audiovisual
content, the subtitle file for the original video and generates a subtitle file
which is perfectly in-sync with the clean recording. The tool takes about 25 seconds
to create a synced subtitle file so that the viewer does not have any burden before the fun
starts.
https://github.com/CCExtractor/Subtitle-Resync
Why audio fingerprinting?
There is lot already written and discussed over the internet on what is audio fingerprinting. To start
with,
here is what wikipedia has to say. An acoustic fingerprint is a condensed digital summary, a fingerprint,
deterministically generated from an audio signal, that can be used to identify an audio sample.
Practical uses of acoustic fingerprinting include identifying songs, melodies, tunes etc. YES! this is
what the magical
Shazam
uses to recognize a song from the cosmic corpus of audio.
Our project uses chromaprint, an open source audio fingerprinting library. It works with spectrograms, which are visual representations of the spectrum of frequencies in a sound as these vary with time. Chromaprint converts the input audio to the sampling rate of 11025 Hertz and using a FFT(Fast Fourier Transform) window size of 4096 with a 2/3 overlap. The algorithm behind chromaprint is complex. Nevertheless, the audio fingerprint are array of 32-bit integers. These are hashes of some arbitrary audio features over a short period of time. A new hash is generated every 0.1238 seconds and each hash covers 2.6 seconds of audio.
The audio fingerprints look like this:
1
2
3
array([3208039586, 3207744690, 3207744642, 3177323714, 3187031106,
2650221586, 2650025010, 2683053106, 2682795042, 2594778150,
2594909479, 2594782997, 2594709188, 2326298244])
The further processing of these audio fingerprints rarely deal with them in this form, instead it can be thought of as a 2D black-and-white image. Black is a 0 bit and white is a 1 bit.

How has this anything to do with subtitles?
Audio fingerprints are generated for both the audio files, then we compare different sections of original audio to the modified audio, based on which we identify the different segments of the original video. Using the time information of each segment we parse and adjust the subtitles.
-
How are fingerprints compared?
The naive way to compare two fingerprints is to XOR the hashes and count the number of non-zero bits in the result. If you have two identical fingerprints, the result will be zero. If you have two completely different fingerprints, you will see around 50% split between zero and non-zero bits, i.e. the number of non-zero bits will be about 16 for every hash. Which results in very poor results. Obviously the fingerprints of the two files have different timings, thus the hashes we extract out of the original sample will have an offset that is relative to the modified sample.
-
Aligning the Fingerprints We will use a small subset of bits from the hashes and cross-match the two fingerprints. For each hash that appears in both fingerprints, we will calculate the difference of offsets at which they appear in the fingerprints. We build a histogram of these offset differences, do some filtering (effectively estimating a density function using gaussian kernels) and find peaks in it. The peaks will tell us how do we need to align the two fingerprints to find matching segments in them
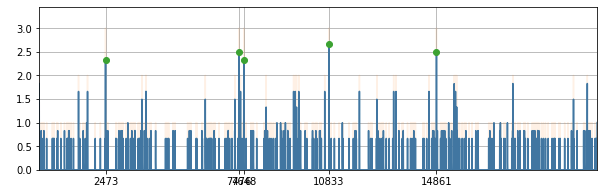
- Finding matching regions For this we XOR the aligned fingerprints, and calculate the bit error rates and apply a gaussian filter with a relatively large kernel. Taking the gradient, we find the local maxima/minima. These result in the segment boundaries.
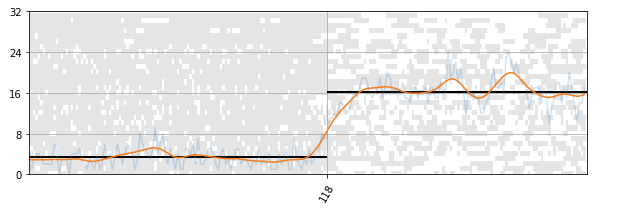
This is how we segment our original files.
Testing the Tool
For testing the tool, I have used a server which was provided to me by my organization
which has a ample amount of samples. Quantitatively speaking, to test the tool’s speed
and accuracy I have used 16 different valid sample files. Out of the files used
I have got accurate results for 13 samples, 2 sample gave a partial result (perfect results upto 70% of the video) and a sample on which
the tool fails to work. Moreover, it takes an average 27.5 seconds to produce the results.
The reason behind the 2 failing results is the section which decides on the basis
of comparison results of fingerprints whether it’s a match, a local match or a no match.
What can be improved?
The project over the course of time will keep improving. The improvements that I would like to make in the near future are:
- Currently for the computation of FFT, I have used kissFFT, a lightweight easy to use open source library. I would like to to replace it with FFmpeg’s FFT functions which would make the fingerprint generation process faster.
- The final steps of deciding the match results definitely are to be improved. As mentioned in the Testing
section there are a few cases which are not producing results due to the wrong deduction.
Also, contribution of any kind is more than welcome. If you have any idea or an issue feel free to open a PR or an issue in the project repository.
Conclusion
I have developed this project during Google Summer of Code, 2019 which I was fortunate to participate in
under CCExtractor Development. Obviously a lot more can be and will be done on this but I am glad that finally I
have an open source project. I am grateful to my mentor
Carlos Fernandez Sanz who gave me this opportunity and helped me throughout my journey.
I hope that anyone reading this will check out the Subtitle-Resync project and drop a few starts on me, or better yet, fork it!
https://github.com/CCExtractor/Subtitle-Resync
So long!